Convenience vs. Probability Sampling in UX Research 便利抽樣與機率抽樣在使用者體驗研究中的應用
選擇研究物件的方法很重要,它會影響研究結果是否可靠。目前,大多數做使用者體驗研究的人喜歡用便利抽樣,就是找容易接觸到的使用者來參與研究。這樣做既省時又省錢,而且能發現主要的使用問題。不過,如果你想讓研究結果能代表所有使用者的情況,最好使用機率抽樣的方法。
Convenience Sampling 便利抽樣
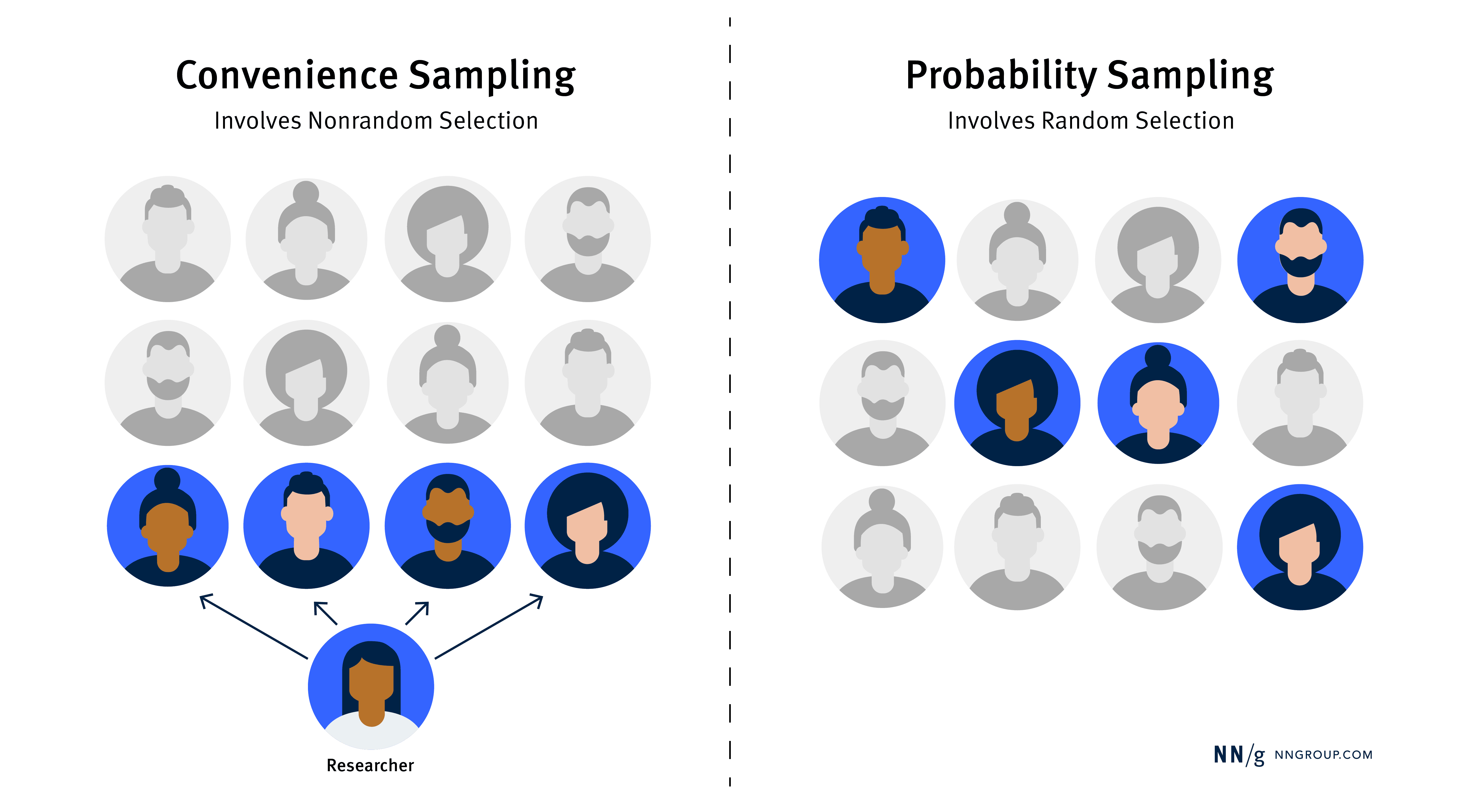
便利抽樣就是選擇容易找到的人來參與研究,而不是隨機選擇。這意味著不是每個目標使用者都有同樣的機會被選中參與研究。
讓我們用簡單的方式來理解:便利抽樣是找容易接觸到的人來參與,而機率抽樣則是隨機選擇,讓每個人都有機會被選中。
常見的便利抽樣方式包括:
- 透過郵件、社交媒體邀請
- 從使用者資料庫中選擇
- 使用研究平臺招募
- 網站上直接邀請
注意事項:
- 設定篩選條件不等於隨機抽樣
- 避免找同事測試,他們的反饋可能有偏差
- 固定配額仍可能受參與者個人因素影響
機率抽樣 Probability Sampling
機率抽樣基於隨機選擇。每個人被選中的機率可以相等或不同(如手機使用者12%,電腦使用者20%),這樣可以平衡不同背景使用者的差異。這種方法讓研究結果更有代表性,減少偏差。
例如:測試電子病歷系統時,團隊按年齡和專業隨機選擇參與者,以平衡技術熟練度的影響。
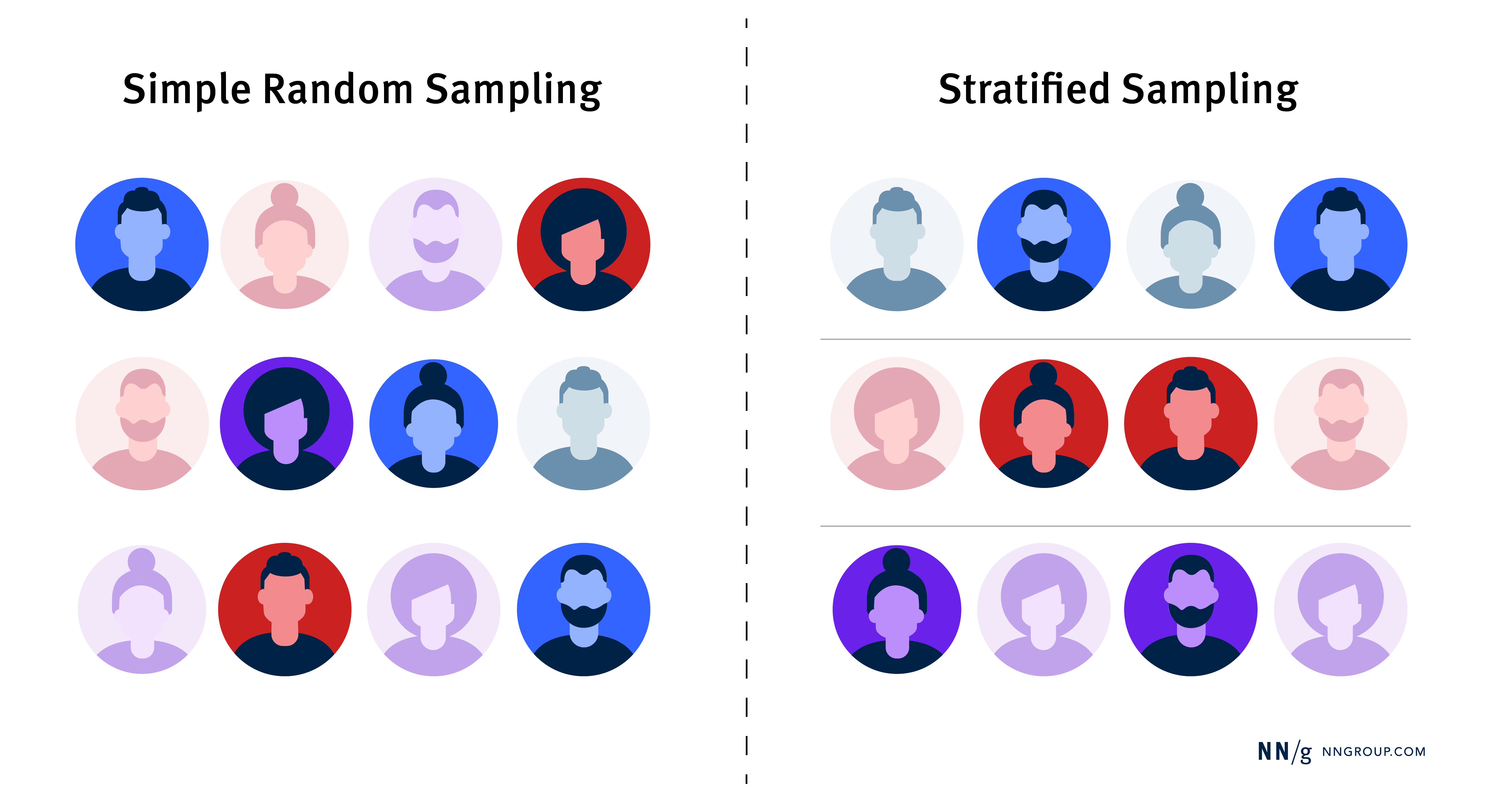
主要有兩種:簡單隨機抽樣和分層抽樣。
Simple Random Sampling 簡單隨機抽樣 :每個人有相同的被選中機會,如從去年使用者中隨機抽100人。
Stratified Sampling 分層抽樣 :先把使用者分組(如新手/熟手),再從每組隨機選擇,確保各類使用者都有代表。
Steps to Gather a Probability Sample 機率抽樣的步驟
機率抽樣比便利抽樣更復雜和耗時。你需要確定這4點:
- 目標人群:明確你想研究的群體範圍。
- 如何獲取完整名單:需要有所有目標使用者的聯絡方式。
- 抽樣方法:選擇簡單隨機抽樣還是分層抽樣等。
- 樣本大小:樣本要夠大才能得到可靠結果。建議定量測試至少40人,問卷調查至少100人。
When You Can Get a Complete List 能獲取完整使用者名稱單的情況
有些情況下可以接觸到明確的使用者群體:
- 現有客戶:可以從CRM系統中抽樣。
- 企業員工:企業內部研究可獲得完整員工名單。
- 專案參與者:如在校學生或福利計劃參與者,可透過郵件等方式聯絡。
When You Can't Get a Complete List 無法獲取完整使用者名稱單的情況
很多情況下無法獲得完整的使用者名稱單,比如:
- 電商網站訪客:大多數訪客沒有登入,無法獲得聯絡方式。
- 新功能潛在使用者:這些使用者還不在系統中。
- 流失使用者:聯絡方式可能已失效或從未獲得。
這些情況下只能使用其他抽樣方法。
Choosing the Right Sampling Method 如何選擇抽樣方法
| 便利抽樣 Convenience Sampling | 機率抽樣 Probability Sampling | |
| 抽樣方法 | 非隨機:基於參與者的可及性和意願 | 隨機:每個群體成員都有被選中的機會 |
| 偏差程度 | 高:樣本可能不具代表性 | 低:目標是代表整體人群 |
| 推廣性 | 有限:結果難以推廣到更大群體 | 高:結果可以推廣到目標人群 |
| 使用場景 | 快速迭代研究和可用性測試 | 大規模使用者研究和重要決策驗證 |
| 成本時間 | 低成本,實施快速 | 成本高,耗時較長 |
| 潛在問題 | 選擇偏差,代表性不足 | 操作複雜 |
When Convenience Sampling Is Sufficient 何時使用便利抽樣
便利抽樣是使用者體驗研究中最常用的方法,因為大多數研究只需要發現使用問題,而不需要統計推論。
適用場景:
- 發現可用性問題:小規模測試就能找出主要問題
- 需要快速反饋:早期研究階段需要快速收集使用者意見
- 無需測量普遍性:探索性研究不需要精確的人群代表性
1. 新版功能的快速可用性測試
產品:某社交媒體 App(如 Instagram 推出“協作發帖”功能)驗證使用者是否能順利找到並使用這個新功能
方法:招募 5-8 位在辦公室附近或線上願意參與的現有使用者,快速觀察使用過程
原因:快速上線前驗證關鍵互動點、不需要代表全體使用者,只需發現“是否容易出錯”、“哪一步最卡殼”
2. 原型測試 + 概念驗證
產品:一個早期的 AI 寫作工具(如 Notion AI Beta 版)探索使用者是否理解“生成式段落”和“重寫句子”的區別
方法:請身邊的同事、朋友或現有使用者,使用 InVision / Figma 原型參與 Zoom 遠端測試
原因:此階段還沒上線,不追求代表性,更關注“使用者是否理解”、“操作流暢性”等認知體驗
3. 快速使用者訪談
產品:內容平臺(如小紅書/Reddit)在探索「創作者激勵方案」瞭解頭部和腰部創作者對於現有變現機制的看法
方法:在社群裡發通知,願意參加 Zoom 訪談的就安排
原因:目的是獲取思路、痛點、情感反應,不做定量統計,用於產品早期共情、策略方向驗證
When to Use a Probability Sample 何時使用機率抽樣
在某些情況下,僅使用便利抽樣可能產生誤導性結論。如果需要可靠的結果來反映整體使用者群,建議使用機率抽樣。
適用場景:
- 需要群體層面推論:評估行為普遍性或比較不同群體時
- 使用者群體多樣:避免某些群體(如技術熟練者)被過度代表
- 決策風險高:涉及重大產品決策,如醫療、汽車等行業
- 需要統計比較:測試不同群體間的差異假設
1. 大規模 UX Benchmark 研究
產品:支付寶希望知道“老年人使用者”的整體操作成功率,確定是否需要推出專門的“簡潔模式”
方法:從擁有實名認證資料的老年人使用者中,按性別、年齡、城市分層抽樣,每組抽取等比例樣本,進行遠端任務測試和問卷調查
原因:希望從數百萬老人使用者中準確估計可用性問題比例、結果將決定是否開發一條新的產品線,屬於高決策影響
2. 不同使用者群的對比實驗
產品:Google Docs 想測試「評論引導功能」是否對不同職業使用者有不同影響,比較教師 vs 商業使用者,在新功能下的使用頻率差異
方法:從不同職業標籤使用者中,使用分層隨機法抽樣進行 A/B Test
原因:要進行顯著性分析,確保資料可泛化,不同職業群體需要均衡對比,避免某類人被過度代表
3. 高風險產品改版
產品:銀行 App 準備全面改版使用者轉賬路徑
目的:確保新路徑不會造成使用者誤操作或安全感下降
方法:隨機從全年齡段、不同收入水平、城市等級中抽樣,進行線上任務驅動測試並記錄完成率和情緒指標
原因:涉及使用者資產與信任,錯誤代價極高,法規要求特定群體必須參與(例如老年人、低學歷使用者)